

.jpeg)
Si alguna vez has escrito "Pinterest scraper" en un motor de búsqueda, ya sabes lo que estás buscando: una forma confiable y escalable de extraer datos de Pinterest y ponerlos en práctica. Ya sea para investigación de tendencias, monitoreo de competidores o alimentar una canalización de IA, el objetivo final siempre es el mismo: datos de Pinterest limpios y utilizables, entregados de manera consistente.
Lo que difiere enormemente es el camino que las personas toman para comenzar a extraer datos de Pinterest.
Algunos optan por un scraper. Otros descubren que una API diseñada específicamente fue la mejor opción desde el principio. Este artículo analiza ambos caminos: cómo se ven en la práctica, dónde falla el scraping y qué herramienta es más adecuada para extraer datos de Pinterest.

Resumen Breve
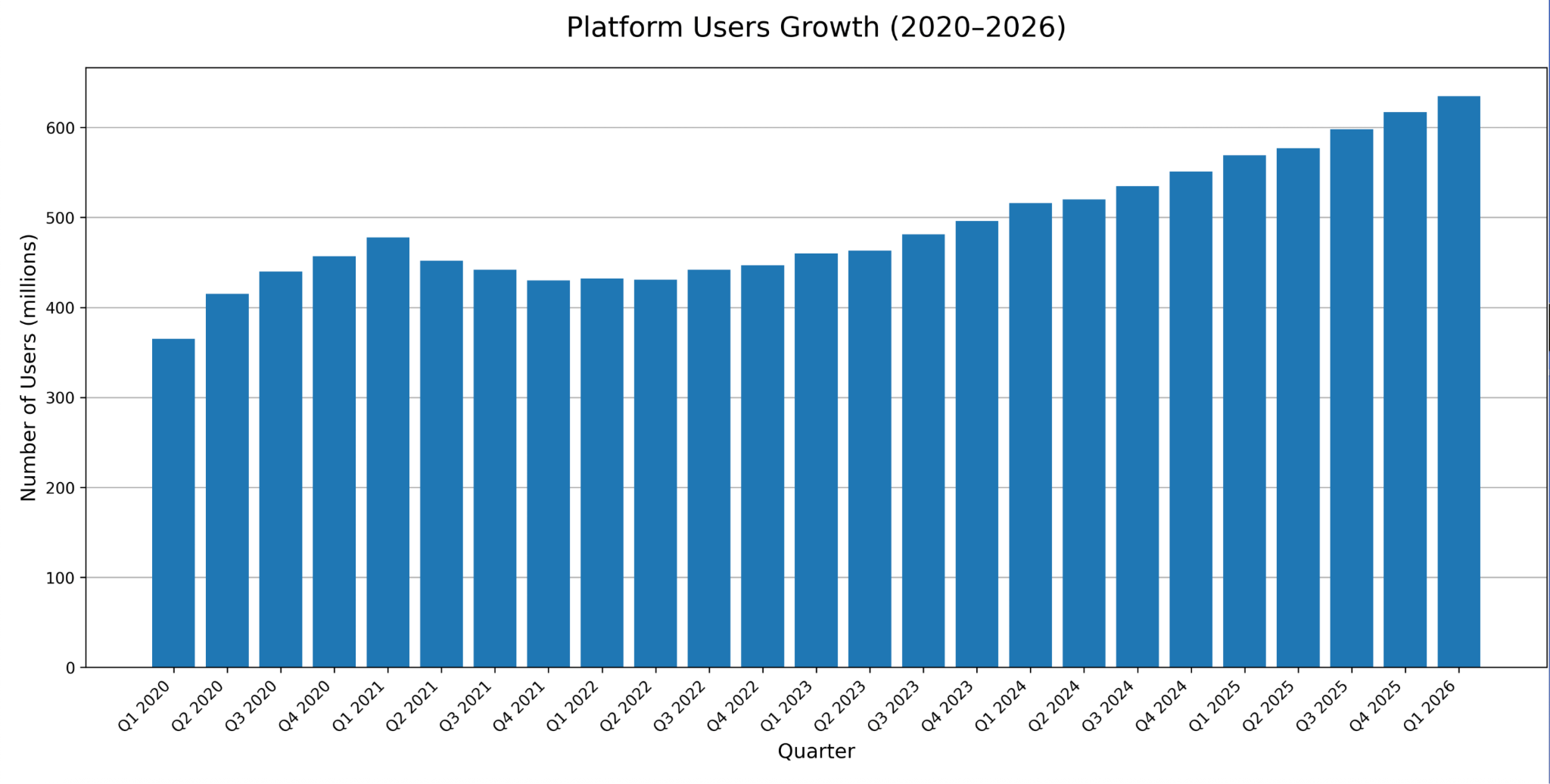
- El informe de ganancias oficial de Pinterest para el cuarto trimestre de 2025 registró 619 millones de usuarios activos mensuales y un crecimiento del 14% en los ingresos, convirtiéndolo en una fuente de datos demasiado significativa para que cualquier investigador de mercado serio, analista de tendencias o estratega de contenido la ignore.
- Los tres enfoques comunes de scraping (scripts manuales, herramientas de código abierto y servicios de terceros) analizan el HTML del front-end de Pinterest, lo que significa que cada actualización de la plataforma los rompe.
- Los scrapers de Pinterest imitan el comportamiento del navegador para extraer datos de la plataforma; tienen una baja barrera de entrada, pero Pinterest contrarresta activamente las acciones automatizadas, lo que dificulta lograr una verdadera escala.
- Automatizar un scraper en un bot no soluciona el problema: lo escala, aumentando el riesgo de detección, la infraestructura necesaria y los costos continuos.
- Una API de Redes Sociales de Data365 proporciona los mismos datos de Pinterest de manera más limpia, rápida y confiable, pero sin la carga de ingeniería, costos impredecibles o fragilidad operativa de los scrapers.
Scraper de Pinterest: Por Qué los Desarrolladores Optan por Él Primero
Un scraper de Pinterest es un programa que extrae datos de Pinterest simulando cómo un navegador o un usuario interactúa con la plataforma. En el fondo, normalmente funciona a través de uno de tres mecanismos:
- analizando el HTML en bruto de las páginas de Pinterest
- interceptando solicitudes HTTP para capturar datos antes de que se rendericen
- ejecutando un navegador sin cabeza como Puppeteer o Playwright para ejecutar JavaScript y extraer el DOM resultante
Existen casos de uso poderosos que impulsan a las empresas hacia el scraping de Pinterest. Las ideas que se difunden en la plataforma necesitan ser rastreadas para ver qué contenido visual está ganando tracción, qué están fijando los competidores y qué cuentas tienen influencia en una categoría.
Pinterest, con sus 619 millones de usuarios activos mensuales a partir del cuarto trimestre de 2025 y una tasa de crecimiento del 14%, es simplemente una fuente de datos demasiado significativa para ignorar (especialmente para marcas que operan en moda, hogar, belleza, alimentos y verticales de estilo de vida donde la plataforma domina).
Entonces, ¿por qué un scraper parece ser el instinto natural inicial? Porque la barrera de entrada es baja. Un desarrollador puede escribir un script básico en una tarde, apuntarlo a una URL de Pinterest y comenzar a extraer datos en pocas horas: sin proceso de aprobación, sin claves de API, sin esperar. Para una rápida extracción de datos única, puede parecer que funciona.
El problema comienza en el momento en que necesitas que siga funcionando.
Formas de Extraer Datos de Pinterest y Por Qué la Mayor Parte de Ellas Fallan
Hay tres rutas principales que los desarrolladores toman cuando deciden obtener datos de Pinterest, así que desglosémoslas cada una.
- Scripts manuales son fragmentos de código personalizados en Python o Node.js que acceden a URLs de Pinterest y analizan la respuesta.
- Servicios de scrapers externos son herramientas independientes que manejan la infraestructura de scraping en tu nombre, abstraiendo la complejidad técnica por una tarifa de suscripción.
- APIs oficiales o de terceros son interfaces estructuradas que proporcionan acceso directo y documentado a los datos de la plataforma sin la gestión de infraestructura y el comportamiento simulado del navegador requeridos.
La tabla de comparación a continuación desglosa las características funcionales de cada herramienta para que puedas elegir si deseas intentar el scraping de Pinterest o optar directamente por la recuperación estable de la API, por ejemplo, con la API de Redes Sociales de Data365.
| Criterios | Script Manual | Servicios de Terceros | API de Data365 |
|---|---|---|---|
| Tiempo de configuración | ⚡ Rápido — un script básico puede estar funcionando en horas | 🕑 Medio — la incorporación varía | ✅ Rápido — puntos finales estables, documentación clara, integra una vez y listo |
| Carga de mantenimiento | ❌ Alta — se rompe con cada actualización del front-end de Pinterest | ⚠️ Media — el proveedor puede manejar parte de ello o no hacerlo en absoluto | ✅ Ninguna — la infraestructura y las actualizaciones son completamente gestionadas del lado de la API |
| Confiabilidad a gran escala | ⚠️ Media — buena para pequeñas cantidades pero se degrada de manera impredecible a medida que aumenta la frecuencia de solicitudes | ⚠️ Media — la confiabilidad depende completamente del tiempo de actividad del proveedor | ✅ Alta — diseñada para cargas de trabajo de producción con 99% de tiempo de actividad |
| Calidad de los datos | ❌ Inconsistente — campos faltantes, URLs rotas y desviaciones de formato | ⚠️ Media — datos incompletos o desactualizados son una queja común | ✅ Alta — salida JSON estructurada, limpia y consistentemente formateada |
| Costo de infraestructura | ⚠️ Disputable — bajo para comenzar pero no incluye servicios adicionales | ⚠️ Media — precios de pago por uso o complicados basados en unidades de computación | ✅ Predecible — un modelo de suscripción basado en créditos, sin costos ocultos |
| Soporte y SLA | ❌ Ninguno — tú eres responsable de cada falla, cada arreglo y cada alerta a las 2 a.m. | ⚠️ Varía — algunos proveedores ofrecen niveles de soporte, pero los SLA rara vez son exigibles | ✅ Soporte dedicado con compromisos de servicio claros y alguien a quien llamar cuando importa |
La tabla cuenta una historia clara: cuanto más te alejas de un script manual hacia una API estructurada, más confiable, escalable y predecible en costos se vuelve tu canal de datos.
Así que, si no te conformas con menos y deseas ir directamente a una forma funcional de recuperar datos de Pinterest, Data365 está aquí para servirte. Agenda una llamada con nosotros, obtén tu token personal y documentación, y comienza a extraer la información que necesitas.
El siguiente paso lógico que muchos desarrolladores toman es automatizar completamente el proceso de scraping convirtiéndolo en un bot. Y ahí es donde las cosas se complican significativamente.
Bot de Scraping de Pinterest: Cómo la Automatización Complica las Cosas, No las Facilita
Cuando un scraper por sí solo no es lo suficientemente rápido, el siguiente paso lógico parece ser convertirlo en un bot: automatizar el proceso de scraping para que funcione continuamente, a gran escala, sin intervención humana. Un bot de scraping de Pinterest hace exactamente esto: envía solicitudes en paralelo, navega por las páginas automáticamente y trata de cosechar datos en masa.
El problema es que todo lo que ya era difícil sobre el scraping se vuelve dramáticamente más complicado cuando agregas automatización.
Los sistemas de detección de bots de Pinterest están ajustados para identificar exactamente este tipo de comportamiento. Volúmenes de solicitudes inusuales, patrones de navegación no humanos, acceso repetido desde la misma IP y tiempos de sesión sospechosos son señales que activan la detección. En el momento en que un bot es marcado, las consecuencias escalan: bloqueos de IP, suspensiones de cuentas, CAPTCHAs que interrumpen la canalización y un fingerprinting cada vez más agresivo que hace más difícil cambiar a una nueva identidad cada vez.
La carga de ingeniería no es trivial. Los datos de la industria sugieren que mantener un bot de scraping a gran escala requiere el equivalente de 5 a 10 horas de tiempo de ingeniería por semana solo para el mantenimiento: reaccionar a los patrones de detección, arreglar flujos rotos y ajustarse a los cambios de la plataforma. Eso es antes de contabilizar la infraestructura real que lo ejecuta.
Compara eso con una llamada a la API que devuelve datos estructurados, limpios y confiablemente formateados en minutos, y la complejidad comienza a parecerse menos a un desafío por resolver y más a un problema a evitar por completo. El flujo de recuperación de tres pasos de la API de Redes Sociales de Data365 es un buen ejemplo de cómo se ve esa simplicidad cuando está diseñada para producción. Veamos cómo funciona.
Automatización del Scraping de Pinterest: Cómo se Ve Realmente la Recuperación Confiable de Datos de Pinterest
Cada negocio que depende de los datos de Pinterest necesita lo mismo de su canal: un proceso que funcione de manera consistente, devuelva resultados limpios y no requiera un ingeniero en espera. Eso no es lo que entrega la automatización del scraping de Pinterest, pero es exactamente lo que hace una API bien estructurada.
La API de Redes Sociales de Data365 utiliza un simple flujo de tres pasos para recuperar datos públicos de pines de Pinterest. Así es como se ve en la práctica:
1. Actualiza los datos a través de una solicitud POST
2. Verifica el estado de la tarea con una solicitud GET
3. Extrae los resultados a través de una solicitud GET
Así es como se ve una respuesta exitosa:
La respuesta regresa como un JSON limpio y estructurado consistentemente con metadatos de pines, métricas de compromiso y detalles de perfil público en una carga útil predecible. Sin análisis, sin campos rotos, sin sorpresas.
¿Qué puedes construir sobre esto? Ahí es donde se vuelve interesante. Una vez que los datos fluyen de manera confiable, las posibilidades de automatización dependen completamente de ti.
- Panel de monitoreo de tendencias
Programa llamadas diarias a la API a través de un conjunto de pines objetivo o tableros de competidores, canaliza las métricas de compromiso en una herramienta como Tableau o Google Looker Studio, y tendrás un panel de inteligencia visual en vivo que se actualiza solo.
- Rastreador de contenido de competidores
Configura un script ligero en Python que extraiga datos públicos de pines de perfiles de competidores semanalmente, almacena los resultados en una base de datos y marca cualquier pin que cruce un umbral de compromiso. Obtendrás una señal temprana sobre lo que está resonando en tu nicho antes de que se convierta en una tendencia que todos los demás ya están persiguiendo.
- Monitor de rendimiento de comercio electrónico
El 83% de los usuarios de Pinterest han realizado una compra basada en contenido que descubrieron en la plataforma, lo que convierte el compromiso con los pines en un indicador significativo de la intención de compra. Conecta la respuesta de la API a tu catálogo de productos y podrás correlacionar automáticamente los datos de guardado y clics de pines con el rendimiento de SKU, brindando a tu equipo de merchandising una línea directa de la actividad de Pinterest a las decisiones de inventario.
El punto no es que estos flujos de trabajo sean complejos de construir, sino que solo son posibles cuando los datos que los sustentan son estables y predecibles. Un scraper no puede darte eso. Una API sí puede.
Entonces, ¿en qué equipo estás: en el de los scrapers o en el de las APIs? Si deseas extraer datos frescos de Pinterest de manera consistente, rápida y confiable, no dudes en ponerte en contacto con nosotros ahora. Discutiremos todos los detalles de tu proyecto específico y encontraremos la mejor solución.
Extraiga datos de cinco redes sociales con la API Data365
Solicita una prueba gratuita de 14 días y obtén más de 20 tipos de datos


.jpeg)






