

.jpeg)
Si vous avez déjà tapé "Pinterest scraper" dans un moteur de recherche, vous savez déjà ce que vous recherchez : un moyen fiable et évolutif d'extraire des données de Pinterest et de les exploiter. Que ce soit pour la recherche de tendances, la surveillance des concurrents ou l'alimentation d'un pipeline d'IA, l'objectif final reste toujours le même : des données Pinterest propres et exploitables, livrées de manière cohérente.
Ce qui varie énormément, c'est le chemin que les gens empruntent pour commencer à extraire des données de Pinterest.
Certains se tournent vers un scraper. D'autres découvrent qu'une API conçue à cet effet était en réalité le choix le plus judicieux depuis le début. Cet article explore les deux voies : à quoi elles ressemblent en pratique, où le scraping échoue et quel outil est le mieux adapté pour extraire des données de Pinterest.

Aperçu rapide
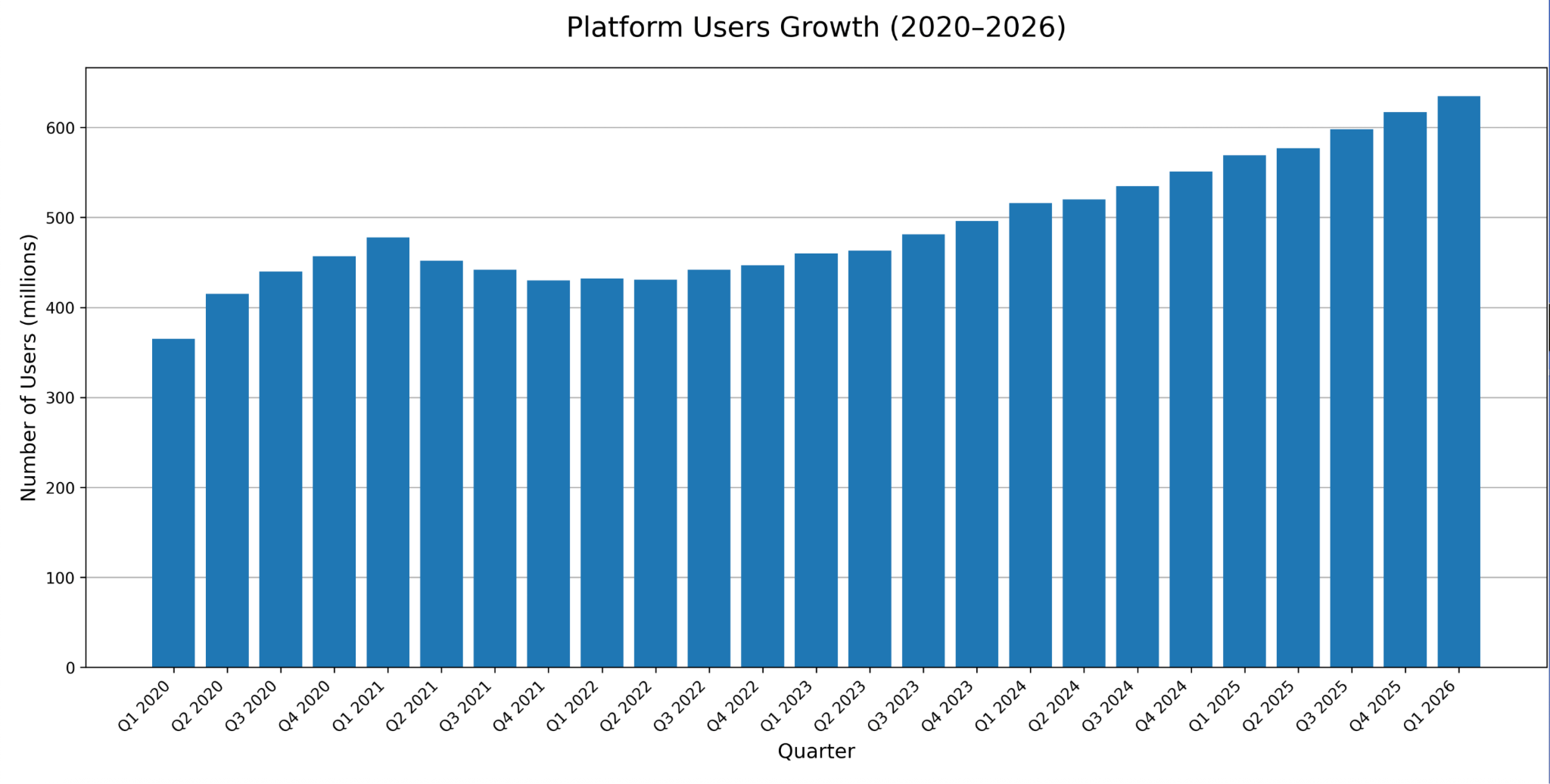
- Le rapport de résultats du quatrième trimestre 2025 de Pinterest a enregistré 619 millions d'utilisateurs actifs mensuels et une croissance des revenus de 14 %, ce qui en fait une source de données trop significative pour tout chercheur de marché, analyste de tendances ou stratège de contenu sérieux pour l'ignorer.
- Les trois approches courantes de scraping (scripts manuels, outils open-source et services tiers) analysent le HTML front-end de Pinterest, ce qui signifie que chaque mise à jour de la plateforme les rend obsolètes.
- Les scrapers Pinterest imitent le comportement des navigateurs pour extraire des données de la plateforme ; cela présente une faible barrière à l'entrée, mais Pinterest contre-attaque activement les actions automatisées, ce qui rend difficile d'atteindre une véritable échelle.
- Automatiser un scraper en un bot ne résout pas le problème : cela l'aggrave, entraînant un risque de détection accru, une infrastructure plus lourde et des coûts continus plus élevés.
- Une API de médias sociaux de Data365 fournit les mêmes données Pinterest de manière plus propre, plus rapide et plus fiable, mais sans les frais d'ingénierie, les coûts imprévisibles ou la fragilité opérationnelle des scrapers.
Scraper Pinterest : Pourquoi les développeurs y ont recours en premier
Un scraper Pinterest est un programme qui extrait des données de Pinterest en simulant la façon dont un navigateur ou un utilisateur interagit avec la plateforme. En coulisses, il fonctionne généralement par l'un des trois mécanismes suivants :
- analyse du HTML brut des pages Pinterest
- interception des requêtes HTTP pour capturer des données avant leur rendu
- exécution d'un navigateur sans tête comme Puppeteer ou Playwright pour exécuter JavaScript et extraire le DOM résultant
Il existe des cas d'utilisation puissants qui poussent les entreprises vers le scraping de Pinterest. Les idées qui se répandent sur la plateforme doivent être suivies pour voir quel contenu visuel gagne en traction, ce que les concurrents épinglent et quels comptes détiennent une influence dans une catégorie.
Pinterest, avec ses 619 millions d'utilisateurs actifs mensuels au quatrième trimestre 2025 et un taux de croissance de 14%, est tout simplement trop significatif en tant que source de données pour être ignoré (surtout pour les marques opérant dans les secteurs de la mode, de la maison, de la beauté, de l'alimentation et du style de vie où la plateforme domine).
Alors pourquoi un scraper semble-t-il être le réflexe naturel ? Parce que la barrière à l'entrée est faible. Un développeur peut écrire un script de base en une après-midi, le pointer vers une URL Pinterest et commencer à extraire des données en quelques heures — pas de processus d'approbation, pas de clés API, pas d'attente. Pour une extraction de données rapide et ponctuelle, cela peut sembler fonctionner.
Le problème commence dès que vous avez besoin qu'il continue à fonctionner.
Les moyens d'extraire des données de Pinterest et pourquoi la plupart échouent
Il existe trois principales voies que les développeurs empruntent lorsqu'ils décident d'extraire des données de Pinterest, décomposons chacune d'elles.
- Scripts manuels : ce sont des extraits de code Python ou Node.js personnalisés qui accèdent aux URL de Pinterest et analysent la réponse.
- Services de scraping externes : ce sont des outils indépendants qui gèrent l'infrastructure de scraping en votre nom, abstraisant la complexité technique contre un abonnement.
- APIs officielles ou tierces : ce sont des interfaces structurées qui fournissent un accès direct et documenté aux données de la plateforme sans gestion d'infrastructure ni comportement de navigateur simulé requis.
Le tableau de comparaison ci-dessous décompose les fonctionnalités de chaque outil afin que vous puissiez choisir si vous souhaitez essayer le scraping de Pinterest ou opter directement pour une récupération stable via API, par exemple avec l'API de médias sociaux de Data365.
| Critères | Script manuel | Services tiers | API Data365 |
|---|---|---|---|
| Temps de configuration | ⚡ Rapide — un script de base peut être opérationnel en quelques heures | 🕑 Moyen — l'intégration varie | ✅ Rapide — points de terminaison stables, documentation claire, intégrez une fois et c'est fait |
| Charge de maintenance | ❌ Élevée — se casse à chaque mise à jour front-end de Pinterest | ⚠️ Moyenne — le fournisseur peut en gérer une partie ou pas du tout | ✅ Aucune — l'infrastructure et les mises à jour sont entièrement gérées du côté de l'API |
| Fiabilité à grande échelle | ⚠️ Moyenne — bon pour de petites quantités mais se dégrade de manière imprévisible à mesure que la fréquence des requêtes augmente | ⚠️ Moyenne — la fiabilité dépend entièrement du temps de disponibilité du fournisseur | ✅ Élevée — conçu pour des charges de travail de production avec 99 % de disponibilité |
| Qualité des données | ❌ Inconsistante — champs manquants, URLs cassées et dérive de formatage | ⚠️ Moyenne — des données incomplètes ou obsolètes sont une plainte courante | ✅ Élevée — sortie JSON structurée, propre et formatée de manière cohérente |
| Coût d'infrastructure | ⚠️ Discutable — faible au départ mais n'inclut pas les services supplémentaires | ⚠️ Moyen — tarification à l'utilisation ou tarification complexe basée sur les unités de calcul | ✅ Prévisible — un modèle d'abonnement basé sur des crédits, sans coûts cachés |
| Support & SLA | ❌ Aucun — vous êtes responsable de chaque échec, de chaque correction et de chaque alerte à 2 heures du matin | ⚠️ Variable — certains fournisseurs offrent des niveaux de support, mais les SLA sont rarement applicables | ✅ Support dédié avec engagements de service clairs et quelqu'un à appeler quand cela compte |
Le tableau raconte une histoire claire : plus vous vous éloignez d'un script manuel vers une API structurée, plus votre pipeline de données devient fiable, évolutif et prévisible en termes de coûts.
Donc, si vous ne vous contentez pas de moins et souhaitez accéder directement à un moyen fonctionnel de récupérer des données Pinterest, Data365 est là pour vous servir. Prenez rendez-vous avec nous, obtenez votre jeton personnel et la documentation, et commencez à extraire les informations dont vous avez besoin.
La prochaine étape logique que de nombreux développeurs prennent est d'automatiser entièrement le processus de scraping en le transformant en bot. Et c'est là que les choses deviennent significativement plus compliquées.
Bot de scraping Pinterest : Comment l'automatisation complique les choses, au lieu de les simplifier
Lorsque qu'un scraper seul n'est pas assez rapide, la prochaine étape logique semble être de le transformer en bot : automatiser le processus de scraping pour qu'il fonctionne en continu, à grande échelle, sans intervention humaine. Un bot de scraping Pinterest fait exactement cela : il envoie des requêtes en parallèle, navigue automatiquement sur les pages et essaie de récolter des données en masse.
Le problème est que tout ce qui était déjà difficile à propos du scraping devient dramatiquement plus compliqué lorsque vous ajoutez l'automatisation.
Les systèmes de détection de bots de Pinterest sont réglés pour identifier exactement ce type de comportement. Des volumes de requêtes inhabituels, des schémas de navigation non humains, un accès répété depuis la même adresse IP et des temps de session suspects sont autant de signaux qui déclenchent la détection. Au moment où un bot est signalé, les conséquences s'intensifient : blocages d'IP, suspensions de comptes, CAPTCHA qui interrompent le pipeline et un fingerprinting de plus en plus agressif qui rend le passage à une nouvelle identité plus difficile à chaque fois.
La charge d'ingénierie n'est pas triviale. Les données du secteur suggèrent que maintenir un bot de scraping à grande échelle nécessite l'équivalent de 5 à 10 heures de temps d'ingénierie par semaine juste pour l'entretien — réagir aux schémas de détection, corriger les flux cassés et s'adapter aux changements de la plateforme. C'est avant de prendre en compte l'infrastructure réelle qui le fait fonctionner.
Comparez cela à un appel API qui renvoie des données structurées, propres et formatées de manière fiable en quelques minutes — et la complexité commence à ressembler moins à un défi à relever et plus à un problème à éviter complètement. Le flux de récupération en trois étapes de l'API de médias sociaux de Data365 est un bon exemple de ce à quoi ressemble cette simplicité lorsqu'elle est conçue pour la production. Voyons cela en action.
Automatisation du scraping Pinterest : À quoi ressemble réellement la récupération fiable de données Pinterest
Toute entreprise qui dépend des données Pinterest a besoin de la même chose de son pipeline : un processus qui fonctionne de manière cohérente, renvoie des résultats propres et ne nécessite pas qu'un ingénieur soit en attente. Ce n'est pas ce que l'automatisation du scraping Pinterest offre, mais c'est exactement ce qu'une API bien structurée fait.
L'API de médias sociaux de Data365 utilise un flux simple en trois étapes pour récupérer les données publiques des épingles Pinterest. Voici à quoi cela ressemble en pratique :
1. Mettre à jour les données via une requête POST
2. Vérifier l'état de la tâche avec une requête GET
3. Extraire les résultats via une requête GET
Voici à quoi ressemble une réponse réussie :
La réponse revient sous forme de JSON propre et structuré de manière cohérente avec des métadonnées d'épingles, des métriques d'engagement et des détails de profil public dans une seule charge utile prévisible. Pas d'analyse, pas de champs cassés, pas de surprises.
Que pouvez-vous construire dessus ? C'est là que cela devient intéressant. Une fois que les données circulent de manière fiable, les possibilités d'automatisation dépendent entièrement de vous.
- Tableau de bord de suivi des tendances
Planifiez des appels API quotidiens sur un ensemble d'épingles cibles ou de tableaux de concurrents, intégrez les métriques d'engagement dans un outil comme Tableau ou Google Looker Studio, et vous disposez d'un tableau de bord d'intelligence visuelle en direct qui se met à jour automatiquement.
- Suivi de contenu des concurrents
Configurez un script Python léger qui extrait les données publiques des épingles des profils concurrents sur une base hebdomadaire, stocke les résultats dans une base de données et signale toute épingle qui dépasse un seuil d'engagement. Vous obtenez un signal précoce sur ce qui résonne dans votre créneau avant que cela ne devienne une tendance que tout le monde poursuit déjà.
- Suivi des performances e-commerce
83 % des utilisateurs de Pinterest ont effectué un achat basé sur un contenu découvert sur la plateforme — ce qui fait de l'engagement des épingles un indicateur significatif de l'intention d'achat. Connectez la réponse API à votre catalogue de produits et vous pouvez automatiquement corréler les données de sauvegarde et de clics des épingles avec les performances des SKU, offrant à votre équipe de merchandising une ligne directe entre l'activité Pinterest et les décisions d'inventaire.
Le point n'est pas que ces flux de travail sont complexes à construire — c'est qu'ils ne sont possibles que lorsque les données sous-jacentes sont stables et prévisibles. Un scraper ne peut pas vous offrir cela. Une API peut.
Alors, dans quelle équipe êtes-vous : celle des scrapers ou celle des API ? Si vous souhaitez extraire des données Pinterest fraîches de manière cohérente, rapide et fiable, n'hésitez pas à nous contacter dès maintenant. Nous discuterons de tous les détails de votre projet spécifique et trouverons la meilleure solution.
Extrayez des données de quatre réseaux sociaux avec l'API Data365
Demandez un essai gratuit de 14 jours et obtenez plus de 20 types de données


.jpeg)
.jpeg)
.jpeg)





